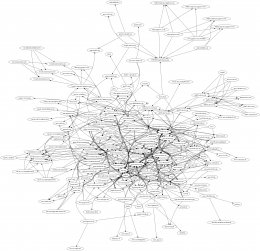
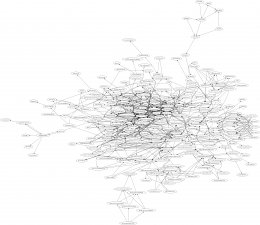
I'm completely new to dot / Graphviz, so I'm still learning.
Post by U.eeAll articles from all groups since January from my server. Sorted and
counted unique paths. Dropped everything below 10 occurrences.
Hum.
I would be concerned about dropping information. I know that there are
some newsgroups that get very low traffic, as in one post every few
months. But that's group specific and probably not as much of an issue
with servers with additional groups.
Post by U.eeSome data was simply noise (containing something other than real
paths), removed those too.
I'm curious to see an example of such.
Post by U.eeBecause I have played it several days or looking back more like weeks
I have tried several things, so little bit is lost, what was exactly
done with specific map (some crappier ones are deleted, some more
amusing specimens are still in my archive).
I get it.
I think that's more the "art" part than "science".
Post by U.eeI tried remove those IP-ADDRESS.POSTED components, same with
not-for-mail and similar.
Did you discard the entire Path? Or just those portions (to the end of
the Path)?
Also, IP-ADDRESS.POSTED is little different than FQDN.POSTED to me.
They are different ways of conveying the same information. The former
didn't have functioning reverse DNS (or it was disabled) and the latter did.
But the posting itself is still a viable article to me.
Post by U.eeI used shell tools (grep, sort, uniq; sed in one point)
I think that such tools are under appreciated.
Post by U.eeand python with pygraphviz.
ACK
Post by U.eeFor graph3-n-20200402.png I generated dot file with python and
"doctored" it manually to remove split clouds. Those small clusters
representing some inner working for some usenet site.
That's what I used sed to normalize those nodes to org names for.
Post by U.eeThen used neato to generate PNG file.
Why neato vs dot itself?
Post by U.eeI probably used bad terminology here, sorry. I felt that PtP describes
it well.
yes, point-to-point is a distinct type of connection. I believe that
the vast majority of NNTP servers are point-to-point connected.
Post by U.eeI meant point-to-point in more general sense, one node having only one
upstream, and upstream node having only one downstream, so similar for
example wireless backhauls.
Ah. I think you're talking about removing things that chain through
each other without branching. E.g. remove n2 & n3 below.
[n1]---[n2]---[n3]---[n4]
You wanted "significant nodes" (which interconnect three or more other
nodes). E.g. remove n2 below.
[n5]
|
[n1]---[n2]---[n3]---[n4]
|
[n6]
Where remove can mean collapse into the larger organization.
Post by U.eeI am not well versed with twitter. Your map there looks nice!
Thank you.
Post by U.eeBecause I used python and converted all data to python data structures
(dictionaries and sets), filtering was somewhat easy.
Hum.... The old unix admin in me has concerns about loading all of that
data into memory. Conversely, other than sort and dot, much of what I
did was based on streaming data through and using much less memory at
any given time. Though, such optimizations are not necessarily as
important these days.
Post by U.eeMore "smartness" is needed though, for example in this time I simply
delete specific keys, using hardcoded hostnames.
Please elaborate on what you are deleting. What does it represent in
the Path: header? Why are you deleting it?
Admittedly, the sort / uniq I was doing would remove data. But it was
data that was already represented in my data.
Post by U.eeYes, I removed nodes, but generally not sites (organizations).
ACK
Post by U.eeYou mean that left from news.tnib.de? Nice catch!
:-)
It was luck. My viewer happened to zoom and show it center of the
zoomed view.
Tracking it was more difficult.
Post by U.eeSome time ago I looked into newsreaders (posting agent) statistics and
between groups there was noticeable differences. I think same is true
with paths. Some groups are representative for some other network, for
example fido.
I agree that there is quite likely — what I'm going to call — clustering
of groups & paths to form message flows.
Though remember Usenet's flooding nature.
Post by U.eeSo, now of course question is, do you want this kind hosts show up
in your map.
I would think so.
I'll counter with why would you not want these hosts to show up?
They are articles that flow across Usenet.
I guess it could be that you're mapping a specific part / subset of Usenet.
Likewise.
--
Grant. . . .
unix || die